Choosing an OpenTelemetry backend - Things To Keep In Mind

OpenTelemetry is a Cloud Native Computing Foundation(CNCF) incubating project aimed at standardizing the way we instrument applications for generating telemetry data(logs, metrics, and traces). However, OpenTelemetry does not provide storage and visualization for the collected telemetry data. And that’s where an OpenTelemetry backend is needed.

Cloud computing and containerization made deploying and scaling applications easier. Modern applications make use of modular code and architectures like microservices and serverless. Engineering teams can ship features faster, and any surge in user demand can be met by just spinning up more containers.
But every coin has two sides. While having benefits like smaller engineering teams and on-demand scaling of applications, cloud computing and containerization have also increased operational complexity manifolds. Troubleshooting an application based on a distributed system for performance issues is like finding a needle in a haystack.

Collecting data from applications that can act as signals for troubleshooting performance issues is a practice as old as writing software. The data that helps to analyze performance issues is known as telemetry data. For cloud-native applications, it became a challenge to have a consistent framework for generating telemetry data.
OpenTelemetry solves this problem by creating an open standard for generating telemetry data. Let’s learn a bit about OpenTelemetry.
What is OpenTelemetry?
OpenTelemetry is an open-source collection of tools, APIs, and SDKs that aims to standardize the way we generate and collect telemetry data. It follows a specification-driven development. The OpenTelemetry specification has design and implementation guidelines for how the instrumentation libraries should be implemented. In addition, it provides client libraries in all the major programming languages which follow the specification.
OpenTelemetry was formed after the merger of two open-source projects - OpenCensus and OpenTracing in 2019. Since then, it has been the go-to open source standard for instrumenting cloud-native applications.
The specification is designed into distinct types of telemetry known as signals. Presently, OpenTelemetry has specifications for these three signals:
- Logs,
- Metrics, and
- Traces
Together these three signals form the three pillars of observability. OpenTelemetry is the bedrock for setting up an observability framework. The application code is instrumented using OpenTelemetry client libraries, which enables the generation of telemetry data. Once the telemetry data is generated and collected, OpenTelemetry needs a backend analysis tool to which it can send the data.
Why does OpenTelemetry need a backend?
The founders of OpenTelemetry wanted to standardize two things:
- The way we instrument application code
- The data format of generated telemetry data
Once we have the telemetry data in a consistent format, it can be sent to any observability backend. This provides users the freedom to select any OpenTelemetry backend based on their observability needs.
The aim of OpenTelemetry was always to have a pluggable architecture using which users can build robust observability stacks using additional technology protocols and formats.
Here’s a snapshot showing how OpenTelemetry fits within a microservice-based application and an observability backend.
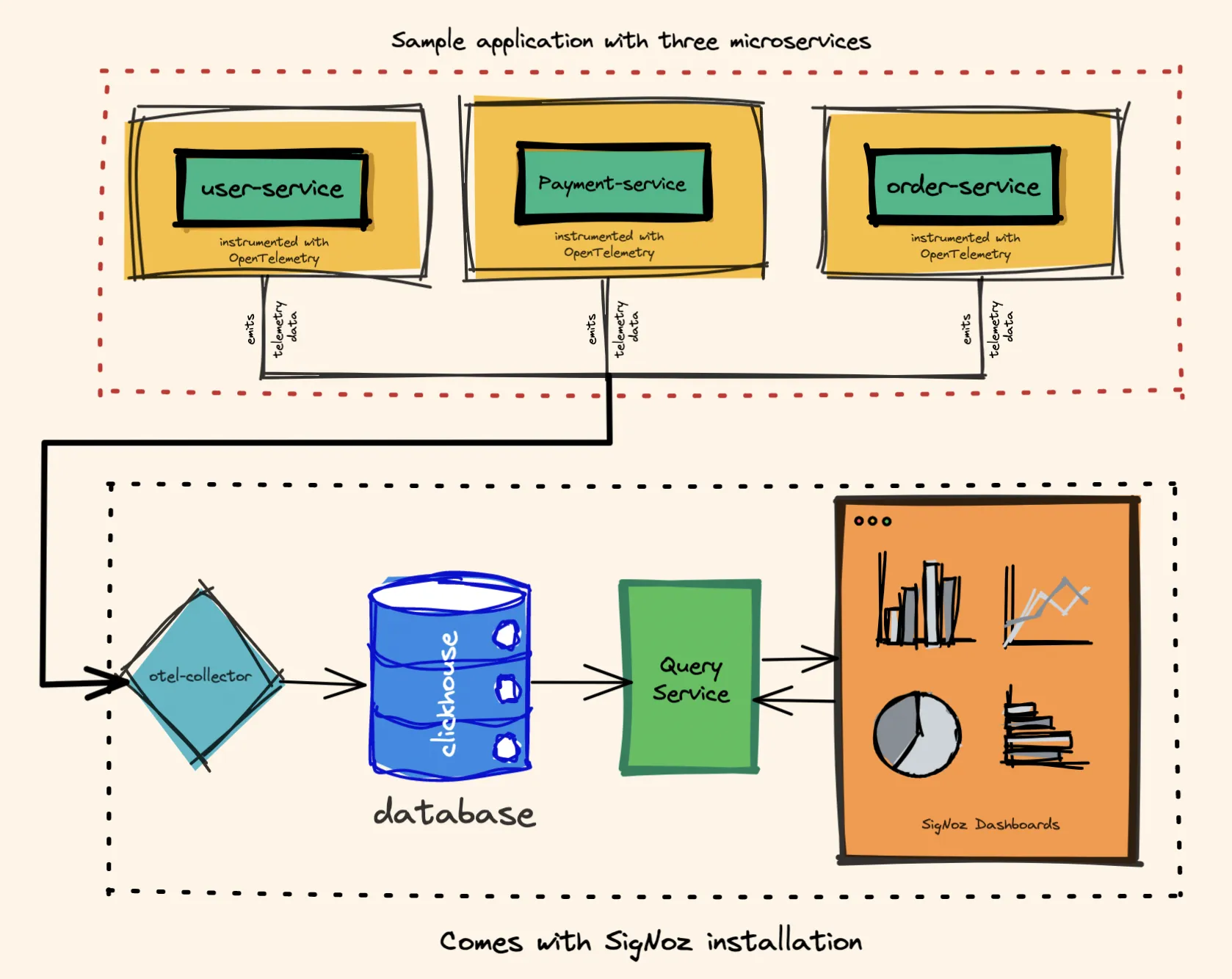
The OpenTelemetry collector acts as the routing layer. Once the telemetry data is collected with the help of OpenTelemetry libraries, it is sent to the OpenTelemetry collector. The OpenTelemetry collector can export the telemetry data in multiple formats to multiple observability backends.
Things to look out for when choosing an OpenTelemetry backend
OpenTelemetry provides you the freedom to choose a backend analysis tool of your choice. Most observability vendors currently have introduced support for OpenTelemetry. So how do you ensure which OpenTelemetry backend to go for? There are three main components that an OpenTelemetry backend is responsible for:
Data Storage
Observability data can be huge. The data storage of an OpenTelemetry backend should be highly scalable, and query execution performance should be top-notch.Query Service
OpenTelemetry has three distinct signals. Each signal has different data formats with different use-cases for users. Moreover, the signals are correlated. The query service of an OpenTelemetry backend should be built with these considerations in mind.Visualization
Making sense out of data is what impacts the end-user of observability dashboards. OpenTelemetry backends should provide intuitive dashboards that enable end-users to take quick actions on performance issues.
Below is the list of factors that should be taken into consideration before selecting an OpenTelemetry backend:
Support for all distinct signals of OpenTelemetry
Currently, OpenTelemetry collects telemetry data in three distinct signals, namely, logs, metrics, and traces. Setting up a robust observability framework requires the use of all three signals. An OpenTelemetry backend should be able to ingest and visualize all three signals. Moreover, the frontend of the OpenTelemetry backend should also provide features to easily correlate the signals.Native support for OpenTelemetry semantic conventions
In OpenTelemetry, every component of a distributed system is defined as an attribute. The attribute is nothing but a key-value pair. These attributes are defined by the OpenTelemetry specification as OpenTelemetry semantic conventions. For example, here is a glimpse of how HTTP conventions look like:Attribute Description Example http.method HTTP request method GET; POST; HEAD http.target The full request target as passed in an HTTP request line or equivalent /blog/june/ http.scheme The URI scheme that identifies the used protocol http; https An OpenTelemetry backend should have native support to store data with OpenTelemetry semantic conventions. Existing observability vendors usually transform the data collected using OpenTelemetry semantic conventions into their propriety formats. But OpenTelemetry has a huge list of semantic conventions which might not be fully utilized in such scenarios.
Should allow aggregates on trace data
Running aggregates on trace data enables you to create service-centric views. OpenTelemetry also provides you the ability to create custom tags. Combined with custom tags and aggregated trace data gives you a powerful magnifying glass to surface performance issues in your services. For example, you can get the error rate and 99th percentile latency ofcustomer_type: goldordeployment_version: v2orexternal_call: paypalOpen Source
OpenTelemetry is an open source standard with a huge community backing. It is testimonial to the fact that community-driven projects can solve large complex engineering problems. It is not necessary for the OpenTelemetry backend to be open source.But having an open source OpenTelemetry backend can enable you to have a full-stack open source solution. Open source solutions have more flexibility, and if you self-host, you don’t need to worry about things like data privacy.
Nearly all observability vendors now claim to be 100% compatible with OpenTelemetry. But it’s difficult to move away from legacy systems. A solution built natively for OpenTelemetry can be a good choice for an OpenTelemetry backend. And that’s where SigNoz comes into the picture.
Top OpenTelemetry Backends
Choosing the right backend for OpenTelemetry is important for efficiently collecting, storing, and analyzing your observability data. Below are some of the top OpenTelemetry backends to consider:
SigNoz
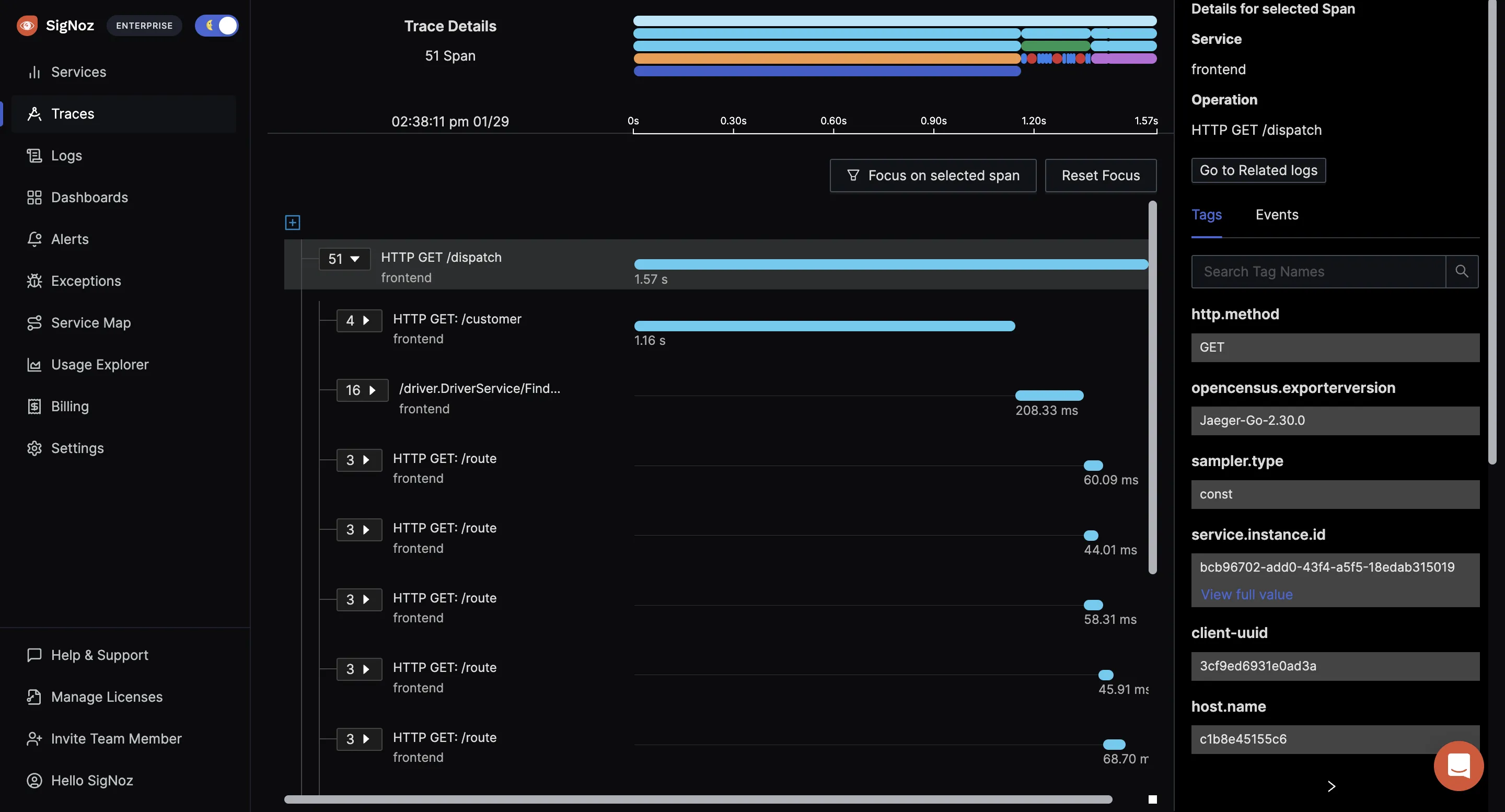
SigNoz is a full-stack open-source APM tool built to support OpenTelemetry natively. It serves as a backend for storing telemetry data (logs, metrics, and traces), provides metrics monitoring, distributed tracing, and logs management under a single pane of glass, and leverages the power of ClickHouse, a columnar database, for highly effective log analytics.
SigNoz is a very good choice for distributed tracing based on OpenTelemetry. With SigNoz, you can do the following:
- Visualise Traces, Metrics, and Logs in a single pane of glass
- Monitor application metrics like p99 latency, error rates for your services, external API calls, and individual endpoints.
- Find the root cause of the problem by going to the exact traces that are causing the problem and see detailed flamegraphs of individual request traces.
- Run aggregates on trace data to get business-relevant metrics
- Filter and query logs, build dashboards and alerts based on attributes in logs
- Monitor infrastructure metrics such as CPU utilization or memory usage
- Record exceptions automatically in Python, Java, Ruby, and Javascript
- Easy to set alerts with DIY query builder
Jaeger
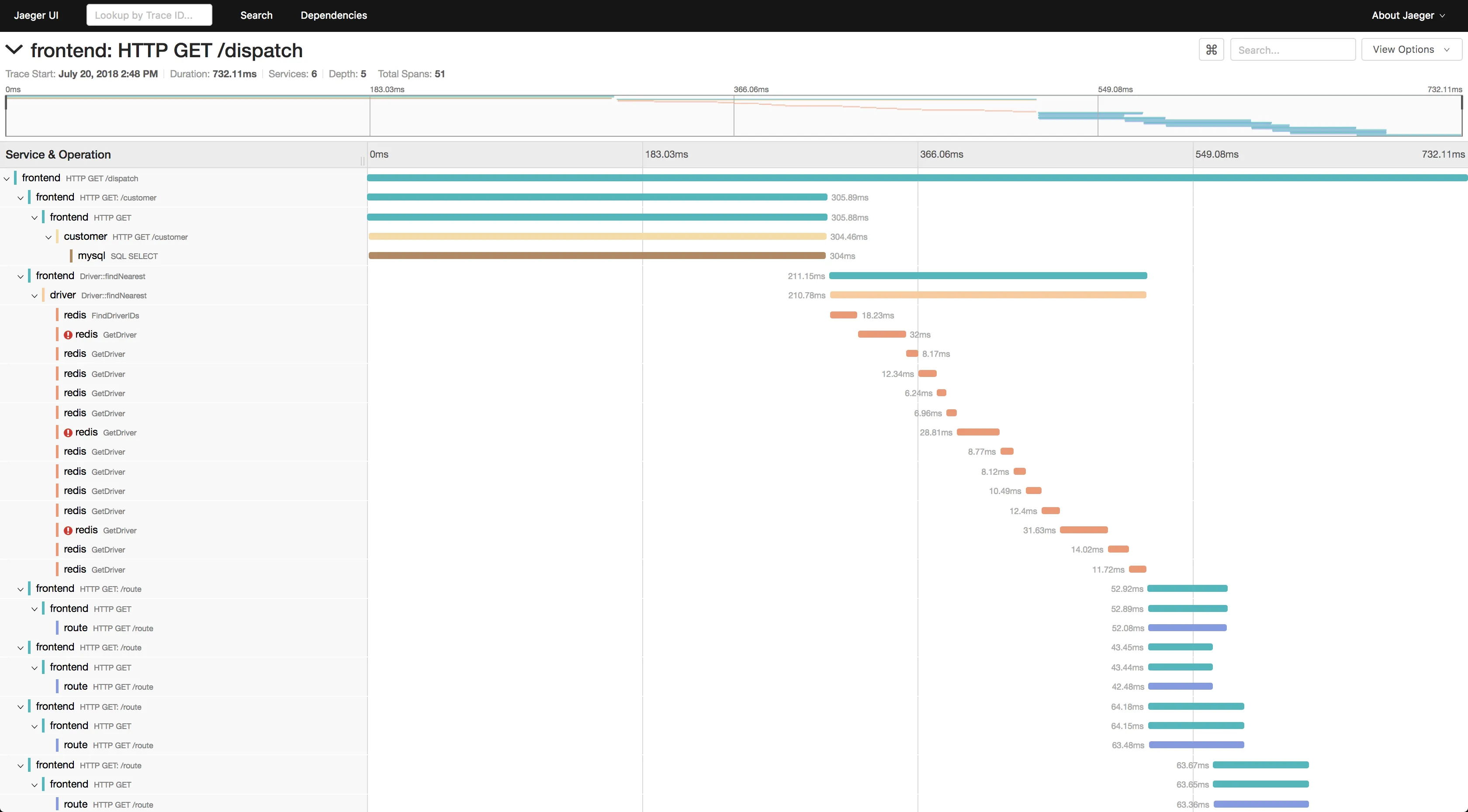
Jaeger is an open-source distributed tracing tool developed at Uber, later donated to the Cloud Native Computing Foundation(CNCF). It is used to monitor and troubleshoot applications based on microservices architecture.
Jaeger is used to store, analyze, and visualize tracing data but it does not support logs and metrics.
Some of its key features include:
- Distributed context propagation
- Distributed transaction monitoring
- Root cause analysis
- Service dependency analysis
- Performance/latency optimization
Jaeger supports two popular open-source NoSQL databases as trace storage backends: Cassandra and Elasticsearch. Jaeger's UI can be used to see individual traces. You can also filter the traces based on service, duration, and tags. However, Jaeger's UI is a bit limited for users looking to do more sophisticated data analysis.
Prometheus
Prometheus is an open-source metrics monitoring and alerting toolkit designed to monitor the performance and health of various components in a distributed system. It excels at collecting time-series data, making it particularly effective for tracking metrics and trends over time. Prometheus employs a pull-based model, where it scrapes data from instrumented applications and services at regular intervals.
If you want to do just OpenTelemetry metrics, then Prometheus can be a good choice.
Some of the key features of Prometheus are:
- Multi-dimensional data model
- A query language called PromQL to query the metrics data collected
- Pull model data collection over HTTP
- An alert manager to handle alerts
The only challenge with Prometheus is its basic visualization layer. You must combine it with a tool like Grafana to get better metrics visualization.
Honeycomb
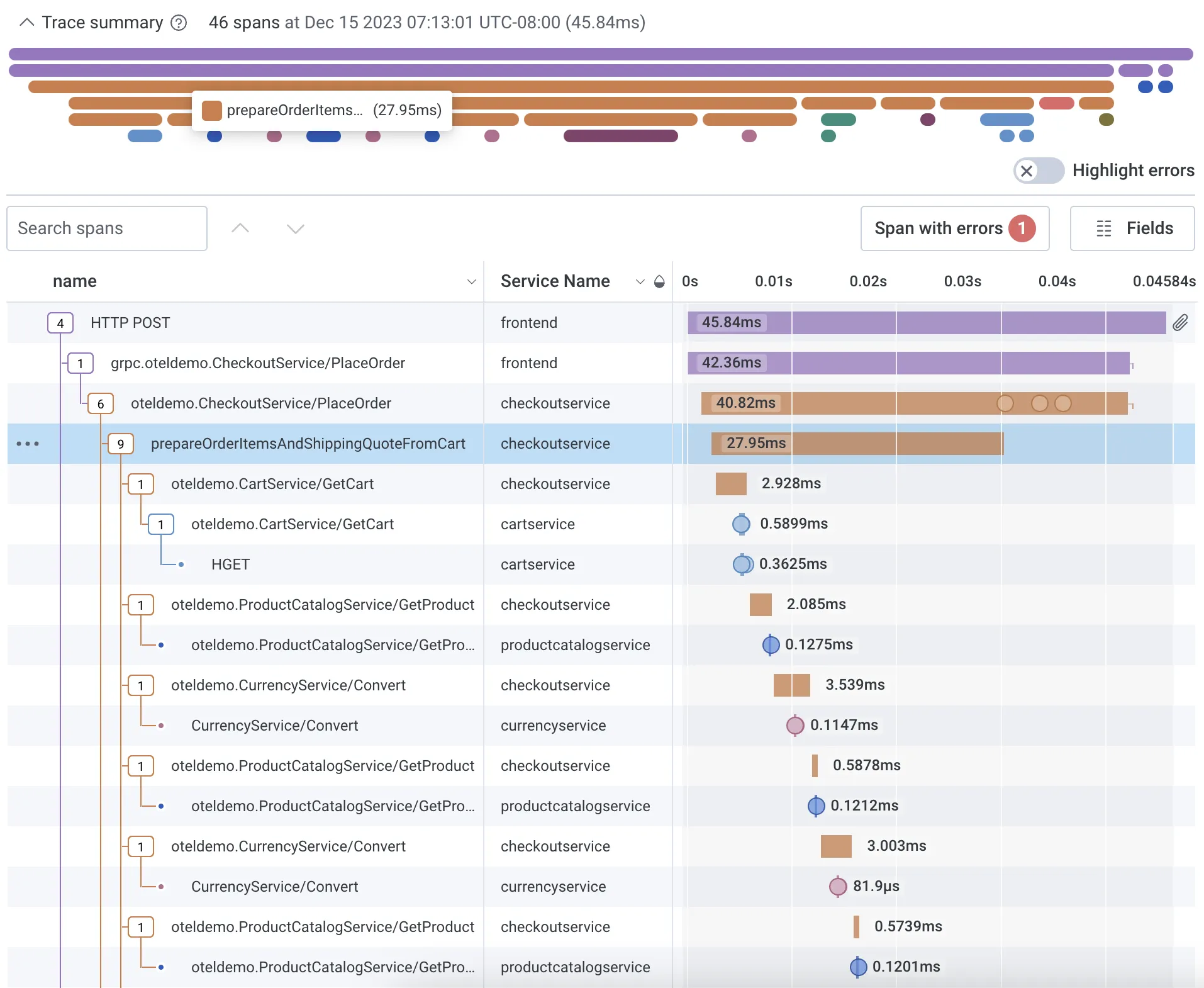
Honeycomb is a full-stack cloud-based observability tool with support for events, logs, and traces. Honeycomb seamlessly integrates with OpenTelemetry, allowing for the collection of telemetry data for storage, visualization, and analysis.
Some of the key features of the Honeycomb include:
- Quickly diagnose bottlenecks and optimize performance with a waterfall view to understand how your system is processing service requests
- Advanced querying capabilities and visualization tools
- Full-text search over trace spans and toggle to collapse and expand sections of trace waterfalls
- Provides Honeycomb beelines to automatically define key pieces of trace data like serviceName, name, timestamp, duration, traceID, etc.
Grafana Tempo
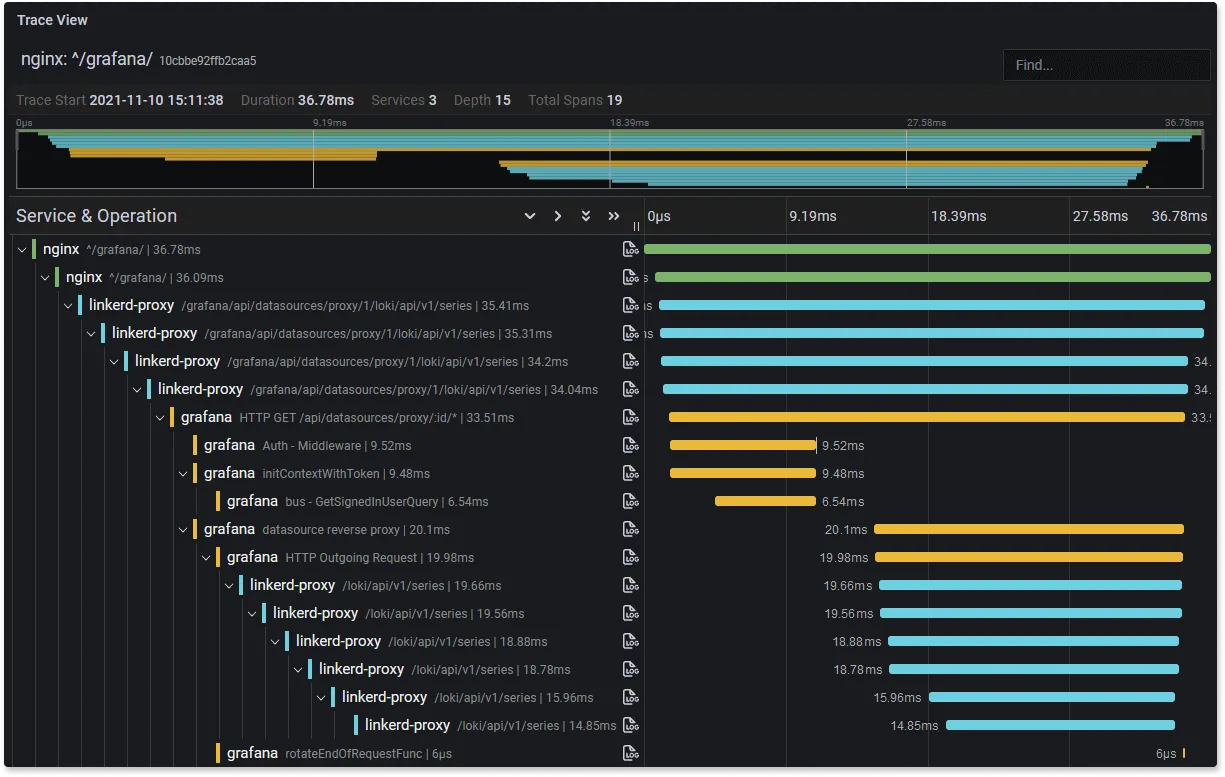
Grafana Tempo is an open-source distributed tracing backend. It is designed to be a scalable and efficient solution for storing and querying traces. It integrates seamlessly with OpenTelemetry to collect and analyze trace data, and with Grafana for visualization of trace data.
Some of the key features of Grafana Tempo include:
- compatible with popular open-source tracing protocols like Zipkin and Jaeger
- Supported by Grafana as a separate data source for trace visualizations
- Available as self-hosted and cloud version
- Provides service graph
Trying out an OpenTelemetry Backend
If you want to play around with an OpenTelemetry backend, it is easy to get started with SigNoz. SigNoz is an open source APM built natively on OpenTelemetry.
SigNoz can be installed on macOS or Linux computers in just three steps by using a simple installation script.
The install script automatically installs Docker Engine on Linux. However, you must manually install Docker Engine on macOS before running the install script.
git clone -b main https://github.com/SigNoz/signoz.git
cd signoz/deploy/
./install.sh
You can visit our documentation for instructions on how to install SigNoz using Docker Swarm and Helm Charts.

Once your application is instrumented with OpenTelemetry client libraries, the data can be sent to the SigNoz backend by specifying a specific port on the machine where SigNoz is installed.
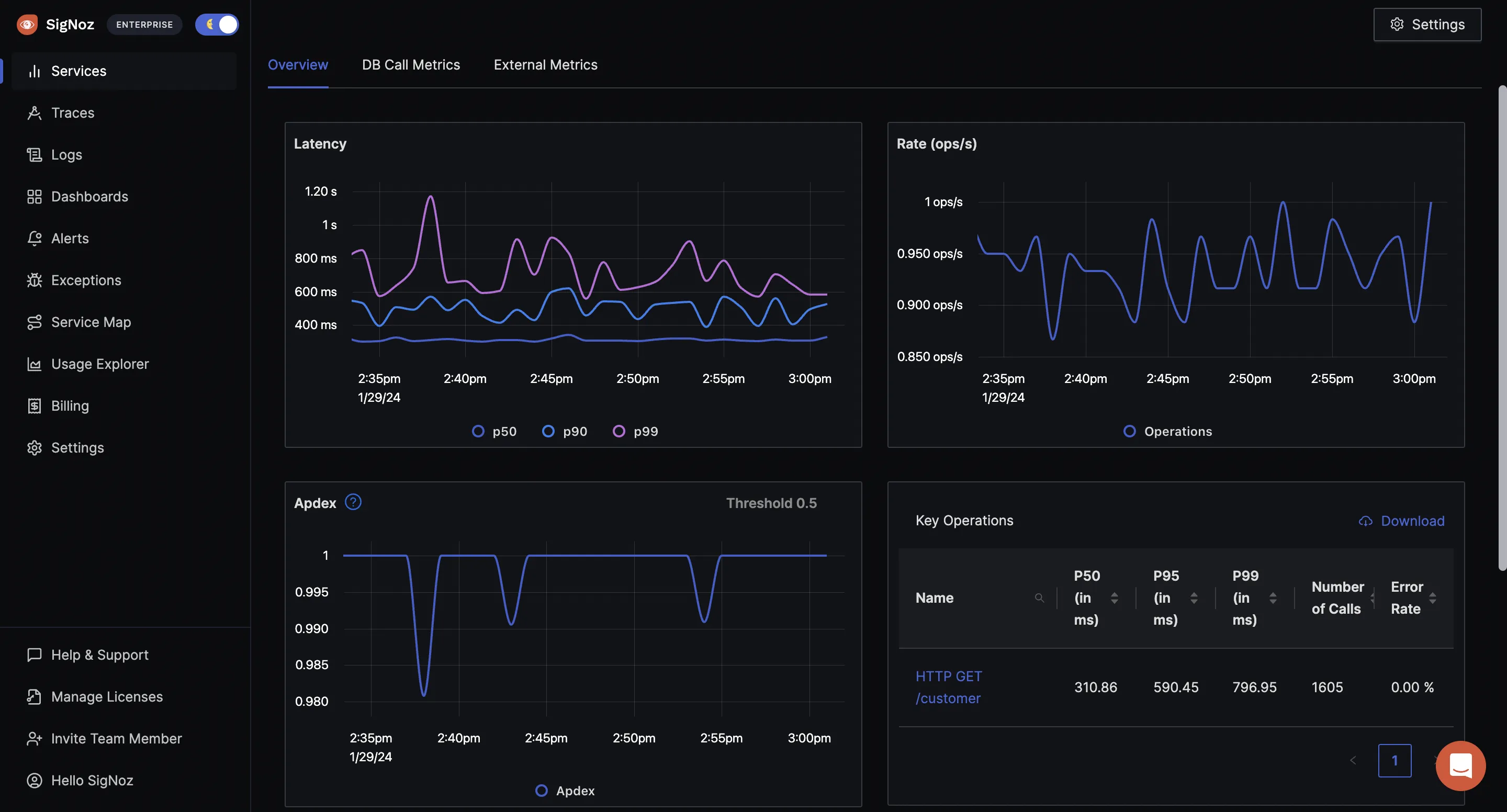
You can then use Signoz to monitor application metrics with out-of-box charts and visualization.
The tracing signal from OpenTelemetry instrumentation helps you correlate events across services. With SigNoz, you can visualize your tracing data using Flamegraphs and Gantt charts. It shows you a complete breakdown of the request along with every bit of data collected with OpenTelemetry semantic conventions.
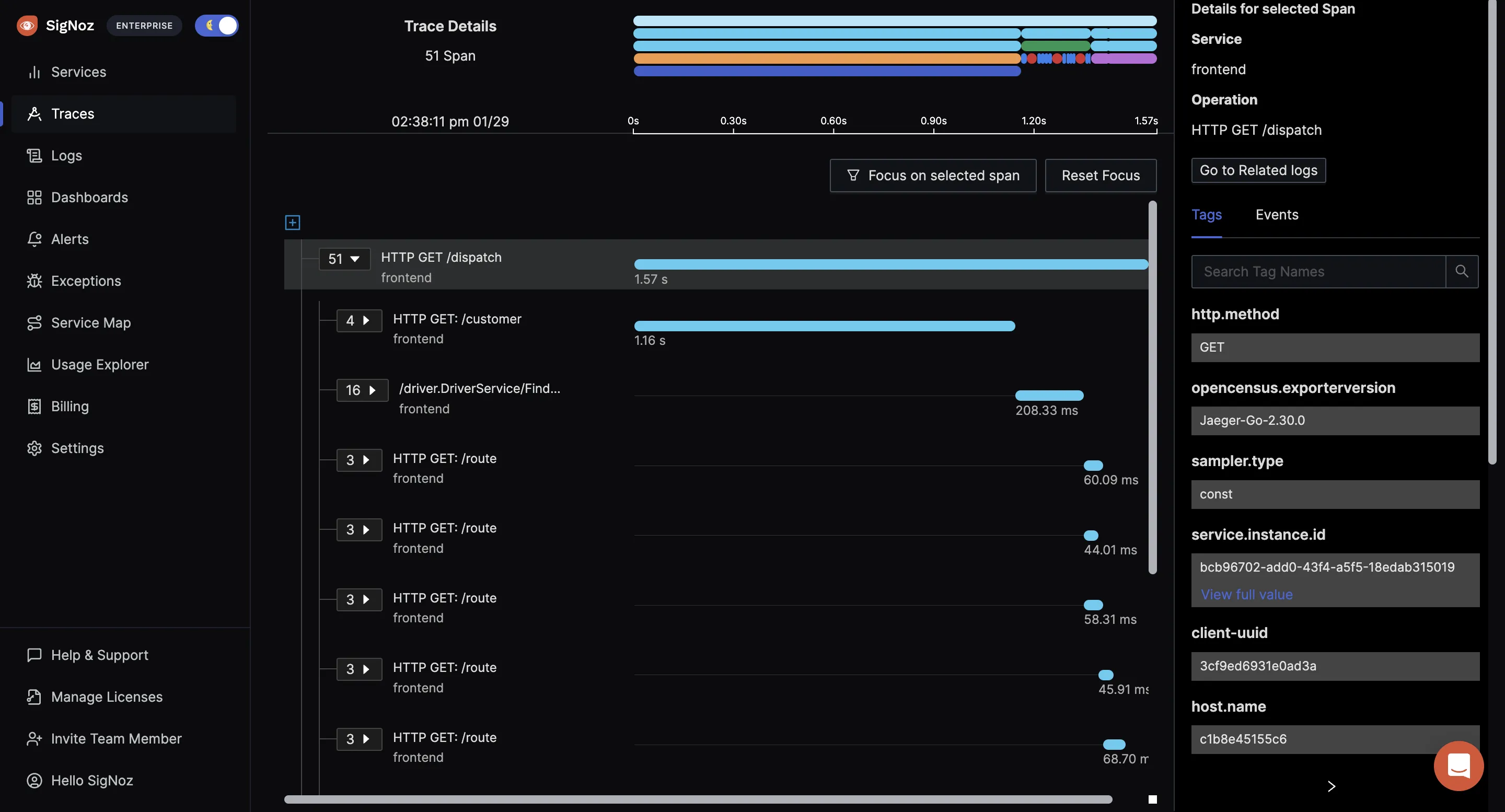
SigNoz also lets you run aggregates on your tracing data. Running aggregates on tracing data enables you to create service-centric views, providing insights to debug applications at the service level. It also makes sense for engineering teams as they own specific microservices.
You can check out the SigNoz GitHub repo here:

